
The love letter contextualised

TL/DR
I proposed legislation and rules should be published with granular structured human readable computer references. I was asked how this compared to existing standards. I looked at 3 different standards ELI (EU), Akoma Ntoso, USLM (US) and found USLM proposes something very similar, ELI specifically states they don’t intend to go as far as I did, Akoma Ntoso has a compatible but (IMO) not as well considered feature. None of them really make the case for WHY this is desirable or what such references enable.
Firstly thanks to all those who shared the love letter and gave feedback. It’s been well received and this is a follow up to some of the responses I received.
Recap
So I built a parser that reads the XML version of legislation from both New Zealand and the EU and generates a dataset at the paragraph (y’all mean different things with that word), and list item level. The point of the exercise was to generate unique human readable, hierarchical, computer references for each data point in the created dataset and most importantly to illustrate why and how such ID’s would be useful.
These references have a sense of hierarchy to them that results in the ability to filter the original document with sub parts of a reference. (i.e. select all of part 1, or part 1 article 3 etc.)
I then extended the dataset to include the minimal amount of fields needed to reproduce the natural language layout of the published versions of the legislation as proof that my dataset was usable and complete.
I also utilised the same dataset to create a REST web api endpoint whose endpoints are designed around the computer references and give machine level access to the natural language rules.
I added anchor tags at the same level of granularity to my web proof to illustrate how they could be utilised for referencing.
I then exported the dataset into a relational database so I could utilise the unique human readable computer references to create relationships between the legislation and commentary, thematic tagging, case law etc.
Finally we layered those relationships back over the web proof to illustrate potential uses.
Your feedback
After I published the love letter I was asked about how what I was doing related to existing standards and solutions. So I’ve taken a deep dive into each of the following. I welcome any feedback on my interpretation of those standards. I’ve selected these standards as ones that overlap with my specific focus of computer references in law. They each are scoped to a specific subset of what I demonstrated and as one would expect from a standard, the why isn’t articulated or demonstrated as I’m attempting to do.
The ones I will touch on are:
- The European Legislation Identifier (ELI)
- Akoma Ntoso / OASIS LegalDocML 1.0
- United States Legislative Markup
The following standards I do not cover here as they do not appear to attempt to address this issue but are the standards used in the legislation I have processed and added referencing to…
- FORMEX (EU)
- The NZ Parliamentary Counsel Office LENZ System
European Legislation Identifier
Organisation and classification system. ELI Goals:
- To make legal data transparent and reliable
- Promote Interoperability and cooperation on legal matters
- Improve search mechanisms for legal professionals and citizens
ELI Utilises
- Http URI’s (identify patterns in the legislation)
- Common Ontology (to describe legislation)
- RDFa (Machine readable format for metadata exchange)
ELI specifically doesn’t want to address computer referencing like I’ve asked for. The model that we created does overlap with a component of the ELI which they specifically state isn’t intended to be as comprehensive as what I’ve set out to achieve. It’s noteworthy that these two different focuses are compatible.
The apparent overlap is where the ELI standard has support for Subdivisions (see eli:LegalResourceSubdivision).
The UK model according to this Good practices and guidelines document looks like:
http://www.legislation.gov.uk/id/{type}/{year}/{number}[/{section}]
Note the [/{section}] at the end hinting at a deeper possible structure. So by way of example the following reference:
https://hamish.dev/experiments/ll/acc/222/en#P1-s6-p1-d6-c-i
rewritten for the ELI might look more like this:
https://hamish.dev/eli/act/2001/0049/20221001/part_1/section_6/paragraph_1/definition_6/listitem_3/listitem_1/en/oj
The ELI standard proposes you can visit a sub url and view a subset of the whole document (see Section 2.2.3). I’m not convinced this is a desirable outcome.
In my approach to reference or view a subset of the document I’ve utilised anchors. That’s the # symbol and everything after it in my example url above. It means the whole document is loaded but at the point of the specific reference. I think it’s preferable to see the part I’m interested in in context to the rest of the document. I would also prefer a single url as the authoritative reading address.
I have however implemented a url system like the ELI proposes but it’s for the API endpoint and much more granular. This is for programmatically accessing the natural language text AND it fits with common API design techniques.
As described by the ELI authors in this not easily referencable PDF in section 3.1.4.:
The ELI ontology is not the following.
- The definitive model to describe legal resources. It is the result of compromises for publishing metadata about legal resources on the web, and as such makes simplifications on the attributes and relations used. Other data models, used internally in editorial systems for example, are much more detailed.
- A document model to describe the structure of the legal documents themselves. ELI captures only the metadata of the documents.
To draw a conclusion from this, the authors of ELI did not seek to achieve what I’m trying to achieve with the Love Letter. In contrast to the above quote, I am specifically making the case that a shared “data model” that isn’t just “used internally” is very desirable and is a complementary but different goal to what the ELI is attempting to solve.
Helpful links:
- https://eur-lex.europa.eu/eli-register/resources.html
- https://eur-lex.europa.eu/content/eli-register/glossary.html
- https://op.europa.eu/en/publication-detail/-/publication/8159b75d-5efc-11e8-ab9c-01aa75ed71a1
Akoma Ntoso
The extensive Akoma Ntoso standard already has the features needed to support the functionality I’m proposing by way of its eId attribute. In saying that, Akoma Ntoso is an XML standard that’s focused on document structure and doesn’t attempt to describe online access or URL based referencing. Akoma Ntoso also has conformance levels and to quote the documentation:
“The use of attribute eId is optional for conformance level 1, and required for conformance level 2 or more”
The immediate takeaway is aiming beyond conformance level 1 should ensure a level of machine referenceability. Because I felt it would be elementary (it was) I added an Akoma Ntoso eId generator to my love letter demonstration. It’s interesting to compare the two outputs with Akoma Ntoso being a lot more verbose but equally more readable.
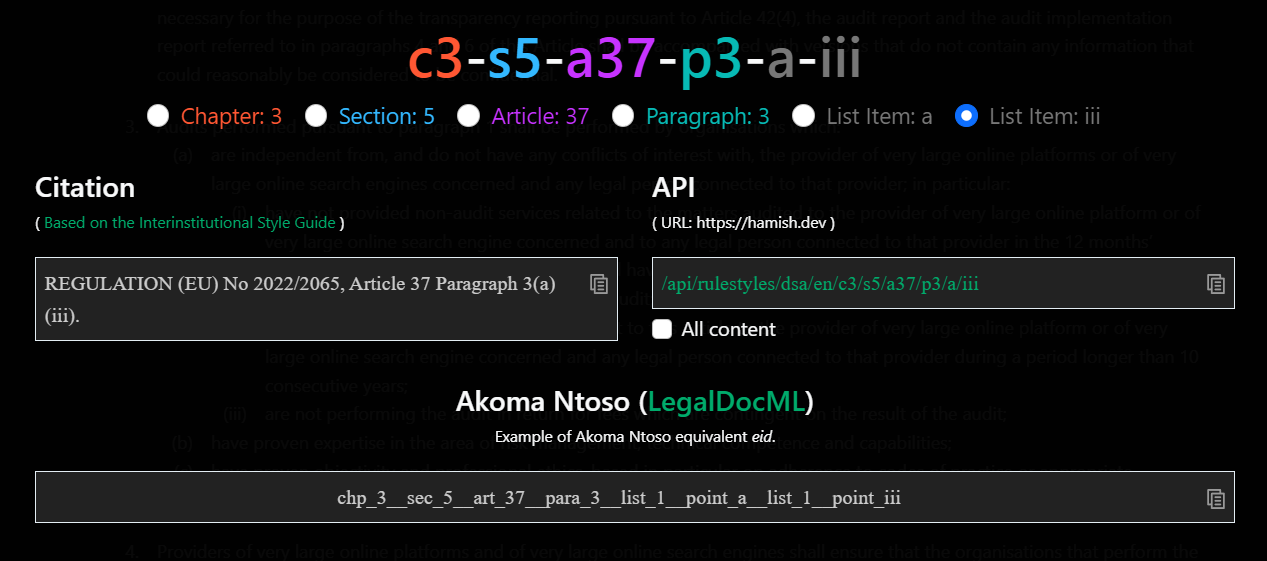
The standard describes how to apply the eId and wId
The standard’s description of the syntax approach to take.
The standard also dictates these abbreviations which are not exhaustive and can be added to.
Finally one super niche point of difference which I find intriguing is that Akoma Ntoso references the list as well as the list item. This results in something like para_3__list1__point_a__list1__point_iii which in my model is described as p3-a-iii. The reason I didn’t include the list itself is that lists always exist in context and scoping the list rather than its parent didn’t seem helpful. I’d be intrigued to find use cases where referencing the list itself is desirable. The next standard I look at USLM also appears to not reference the lists directly.
United States Legislative Markup
This standard has the concept of the @temporalId which essentially almost matches the approach I took. It’s always encouraging to find someone else invented the wheel in a similar fashion to the way you did.
They have a short form and long form list of referencing nomenclature
Like the ELI, they also propose url references that deliver parts of the document (I still prefer this approach more for an API endpoint and in page anchors for human friendly links).
One distinct point of difference is described as follows:
Levels of the hierarchy should be omitted whenever the numbering of a level does not require references to the higher levels. For example, section numbers are usually unique throughout the document, so it is not necessary to use the higher big levels to compute a name. So a section can be identified as simply “s1” rather than “p1_d1_s1”.
This would mean for our Digital Services Act example that the id c2-a9-p2-a-vi could be shortened to a9-p2-a-vi since the articles are numbered continuously through the document. Would I prefer to know Article 9 was in Chapter 2? At this point I’m not that fussed but I think shortening it makes the references less predictable, for example the API endpoints would be less clear to predict. This nuance into the use of these references isn’t likely to have been considered within the context of the USLM.
Wrap up
I hope that provides useful context for the work and thinking I’ve been undertaking. I think it could be fun to build an Akoma Ntoso generator so I could convert EU and NZ law straight into Akoma Ntoso. I also think it could be worthwhile to influence those standards and see more consideration given to computer referencing and how utilisation of those references can inform the direction they should take.
I’m doing this work under the umbrella of the Syncopate Lab along with Tom Barraclough and we’re contemplating how to extend this project to include authoring so we can free the endless PDF based regulations we have to work with. If you’d like to support us or see us push this further please get in touch.
Finally, reviewing these standards has left me realising that maybe we should focus more on the API feature that returns the natural language law that we included in my Love letter; in our research to date apparently they are not a thing.