
“No Notes”

Update: The loveletter implementation this blog post refers to has been removed, to view equivalent material visit: https://ref.synco.pt/nz
I’ve been on a bit of a deep dive with NZ’s legislation in its XML format for nearly two years now and I’m probably a bit more familiar with it than I’d like.
There’s an underlying reason to all my madness, but none of this is actually my goal – just a required building block for the thing I’d like to see in the world.
I’ve got to the point where I can reliably reproduce the New Zealand ACC Act, the Social Security Act and the Social Security Regulations “no notes” as datasets with computer friendly referencing.
When I say “no notes”, I mean it both ways: I’ve excluded the legislative notes for now AND for what I have done, I’ve nailed it to near perfection if I do say so.
In the process of doing this, I’ve found a few interesting nerdy oddities about our law that I want to note here rather than leave in my brain where it will be forgotten. If you’re involved in creating this XML, think of this as a third party critique from someone doing things with it that it was likely not designed for.
These oddities all prompt the same question for me – what is the legal meaning (if any) of things in the New Zealand Law XML that aren’t apparent in official web versions.
Non-breaking spaces
This topic is definitely the least impactful of what I want to cover, but I’ve included it because it in one way required a work around. You may or may not know that in documents there are different types of spaces. I’m talking about the ‘space’ character you get between words. You’ll normally use the space bar to generate these but there’s more than one type. One that is particularly common is known as the non-breaking space. It basically does what it says on the tin and the break in question is whether the space can be used in flowing text that needs to break to a new line.
The html entity you can use for this takes the form and the unicode equivalent is U+00A0. If this nerdy detail is a bit much; just accept that there’s different types of spaces that visually you cannot tell apart and they have different properties in computer systems. Turns out, the New Zealand Government XML has non-breaking spaces specifically added in pretty neat ways. For instance, any date like “13th October 1977” has a non-breaking space between each portion of the date to ensure it remains on the same line.
I appreciate this attention to detail.
However, in the Social Security Act Regulations, I found a couple of titles which look like this:
Subpart 5A — Additional generalU+00A0provisionsU+00A0childU+00A0supportU+00A0payments
I don’t know why they’re used here, but they mess up my layouts at mobile screen sizes (something the legislation.govt.nz site doesn’t attempt to tackle yet). To get around this, I’ve replaced these non-breaking spaces with standard spaces (but only on titles). By way of example, this is #P8-S5A on mobile with non-breaking spaces:
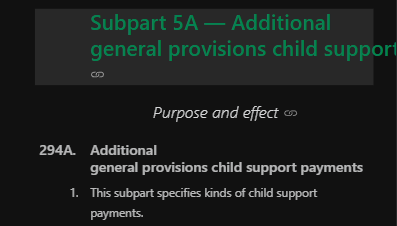
and after replacing with standard spaces:
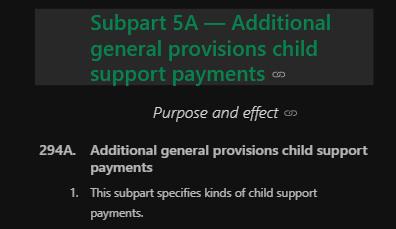
In this specific example I am curious as to whether this is intentional or an oversight.
Tabulated Data
Tables in legislation are surprisingly common. Now, I like some quality tabulated data as much as the next person, but in New Zealand legislation, I think it’s overdone. The render of the tables I’ve developed looks more complicated, but it has an important function. I’ve processed the tables in such a way that there is a unique reference for every table, row, column and cell. I’m proud of what I’ve managed here. Unfortunately, it all starts to fall apart when the tables are used primarily to achieve particular visual layouts, rather than because they structure tabulated data. Tables in New Zealand legislation used for layout use merged cells, lists in cells, and empty columns and rows. At that point, it all starts to feel like it probably shouldn’t have been a table in the first place. Using tables for layouts is reminiscent of old school web design which is no longer practised for reasons applicable here as well.
Here’s some reasonable tables from the Social Security Act:
Here are some not-so-ideal tables with brief notes:
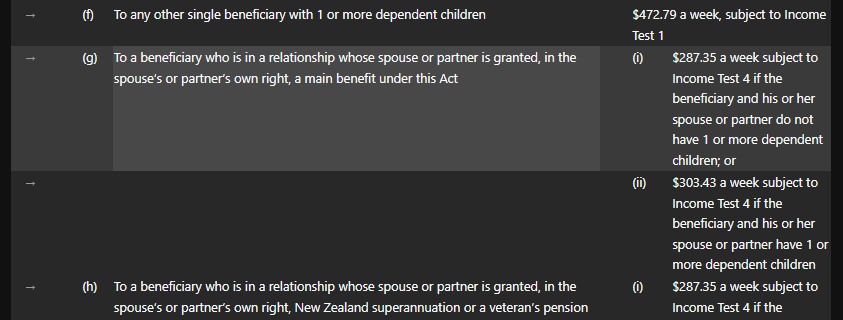
- #sd4-P1-tb1 This is the “jobseeker support” example I refer to below.
- #sd4-P2-tb1 There’s no reason for this content to be in a table.
- #sd4-P3-tb1 Using a table here is more detrimental to the content than a paragraph structure would be.
- #sd4-P4-tb1 Row 1 should become a paragraph with a table. The other rows are paragraphs.
- #sd4-P6-S4-tb1 There’s no reason for this content to be in a table.
- #s399-p1-tb1 All I can say is that this would be fun to redraft.
- #sd4-P7-tb1 This could be done as paragraphs and a series of smaller tables.
These examples illustrate how the tables on legislation.govt.nz are constructed. Sadly, the ‘jobseeker support’ example is also very difficult to reference. For example:
- I cannot provide a computer-readable reference for the whole of
(g)as it spans over two rows. - The reference sd4-P1-tb1-tr9-td2 does not mention
(g), because it’s referencing the table cell in the XML. - It’s not related computationally to
(g)(ii)as it is in the next row.
I’d suggest as a rule of thumb, if you’re giving the text paragraph-style referencing, it should probably not be in a table.
What’s also intriguing to me is that each table has a summary description that doesn’t visually “appear” on the legislation.govt.nz website, but is actually there if you know how to look. It’s a bit like alt text for images on the web. It’s there for usability but unless you know to look, you might miss the descriptions. The summary for the #sd4-P1-tb1 table is:
The following table is small in size and has 4 columns. The columns have no headings.
It’s inconvenient that the actual underlying table technically has 9 columns and is arguably not very small (my version for display purposes has 10 columns, which you can see because I create links using small arrow symbols, with the reference for each row and column).
Finally, with respect to tables, I’ve really struggled to process the widths of table’s columns. Here are the original column measurements (abbreviated for clarity) for the #sd4-P1-tb1 example linked above:
<colspec colwidth="30.00pt"/>
<colspec colwidth="30.00pt"/>
<colspec colwidth="30.00pt"/>
<colspec colwidth="45.00mm"/>
<colspec colwidth="1.71*"/>
<colspec colwidth="17.13*"/>
<colspec colwidth="5.03mm"/>
<colspec colwidth="30.11pt"/>
<colspec colwidth="39.95mm"/>
Despite my best attempts at converting these to percentages and anticipating the different units used, I still get some strange results when creating flexible layouts (which admittedly isn’t something legislation.govt.nz is attempting to tackle yet).
Secret relationships
There are secret relationships present in the digital structure of the legislation I’ve looked at. These are complicated to explain, so I’m going to have to give a couple of examples. They’re also quite intriguing because they create implied relationships between concepts, which aren’t visible on legislation.govt.nz. This is an issue because when I process the XML, I’m creating a structured unique reference system at quite a granular level for the whole document. If the XML doesn’t stay consistent it creates complex logic problems in the software. I’ve managed to successfully code around each of the few inconsistencies that do exist, but I’ve got no way to be confident I’ve interpreted the XML correctly.
So, by way of example, I’ll refer to two definitions in the Social Security Act: income-related insurance payment and income-related purpose. I’m going to have to display some XML to illustrate this. Definitions are laid out roughly like this in the XML:
<def-para id="DLM6784541">
<para>
<!-- definition content here -->
</para>
</def-para>
<def-para id="DLM6784543">
<para>
<!-- definition content here -->
</para>
</def-para>
The first 98 definitions in this schedule follow this pattern. Then, we come to the two examples mentioned, and they take a subtly different approach. Rather than opening a separate definition tag for each definition, it uses one for both. That looks like this:
<def-para id="DLM6784545">
<para>
<!-- definition content here -->
</para>
<para>
<!-- definition content here -->
</para>
</def-para>
This sharing of a def-para tag is only done by these two definitions. Given how I’m generating unique references for these definitions, I end up unsure how to generate a reference that’s meaningful for them.
Up until this point it was easy: d1, d2, d3… d97, d98… now what?
When you look at them on the legislation.govt.nz website there is no indication of this special relationship - they look just like their surrounding definitions:

Here is a direct link to that specific ID so you can check for yourself.
So was this meant to mean anything? There’s kind of two options here. If it’s a glitch, then I suspect it means we have developed a more thorough system for checking the digital publishing of New Zealand legislation than is currently in use. On the other hand, if it is meant to mean something, shouldn’t it be visible in some way on legislation.govt.nz?
Badly formed XML
The legislation also includes some “errors” in the XML which I think are just mistakes, because they otherwise don’t make sense. Oddly enough, this one also involves definitions in the Social Security Act. As shown in the last example, definitions in the XML generally take the form:
<def-para id="DLM6784541">
<para>
<!-- definition content here -->
</para>
</def-para>
But there are seven definitions in the Social Security Act where parts of the definition are placed outside the def-para tag.
The first – the definition of controlled drug is one of these. It looks like this:
<def-para id="DLM6784445">
<para>
<text>
<def-term id="DLM6784446">controlled drug</def-term>—
</text>
<label-para>
<label denominator="yes">a</label>
<para>
<text>is defined in
<citation jurisdiction="nz">
<intref href="DLM6783394" id="LMS107774">section 152</intref>
</citation> for the purposes of
<citation jurisdiction="nz">
<intref href="DLM6783388" id="LMS107775">sections 147 to 152</intref>
</citation>; and
</text>
</para>
</label-para>
</para>
</def-para> <!-- this closing tag should be at the end of this code block -->
<label-para>
<label denominator="yes">b</label>
<para>
<text>has, in
<citation jurisdiction="nz">
<intref href="DLM6783653" id="LMS108177">sections 250</intref>,
<intref href="DLM6783683" id="LMS108178">263</intref>, and
<intref href="DLM6783974" id="LMS108179">411</intref>
</citation>, the same meaning as in
<citation jurisdiction="nz">
<intref href="DLM6783394" id="LMS108180">section 152</intref>
</citation>
</text>
</para>
</label-para>
What this does computationally is it completely separates the Social Security Act 2018, Schedule 2 definition of “controlled drug” (b) from its definition. While (a) is considered a child of the definition tag def-para, (b) is considered a sibling that comes after. Visually on legislation.govt.nz there’s no indication the XML differs in this way:

The definitions affected by this problem are:
- controlled drug
- CYPFA order or agreement
- debtor’s payer
- offence
- open employment
- offence
- parents
- recognised voluntary work
Numbering conventions
I suspect the answer to this issue may be obvious to subject matter experts, but I’m recording it here in case it’s not. The chunks of the legislation that are “Parts” are numbered numerically, i.e. Part 1, Part 2 etc. This is continued in the Schedules, for example Part 1 of Schedule 1. By contrast, in Schedule 12 of the Social Security Act, this approach to Parts switches to using letters so we end up with Part A, Part B and Part C. I can’t see any specific reason for this. The only difference in the XML between the first approach (Schedule 1, Part 1) and the second approach (Schedule 12, Part 1) is that the whole of the Schedule 12, Part 1 is contained within a schedule.misc tag.
Wrap up and what’s next
It looks like I haven’t quite taken this little project as far as it needs to go yet, so I’ll likely be writing about it more in the future. I’m quite keen to take my format and republish a complete NZ Act in the Akoma Ntoso format (LegalDocML). I’m also exploring versioning and of course embarking on building some of the things I want to see in the world that this approach enables.
If you’re interested in this work and have something specific you’d like us to tackle, Tom Barraclough and myself launched Syncopate Lab last week as a vehicle for engaging with us and this work. I suggest you take a look.